Benchmark Data Collection
What does our study do?
We are a group of researchers at the Center for Education Data Science and Innovation, housed at the University of Maryland-College Park (UMD). With support from the Gates Foundation, Walton Family Foundation, and Chan Zuckerberg Initiative, we are creating an open-source, high-quality multimodal dataset using multiple types of information from mathematics classrooms to facilitate the creation of cutting-edge AI models and automated tools for education researchers and practitioners. Housed at UMD, this dataset will feature:
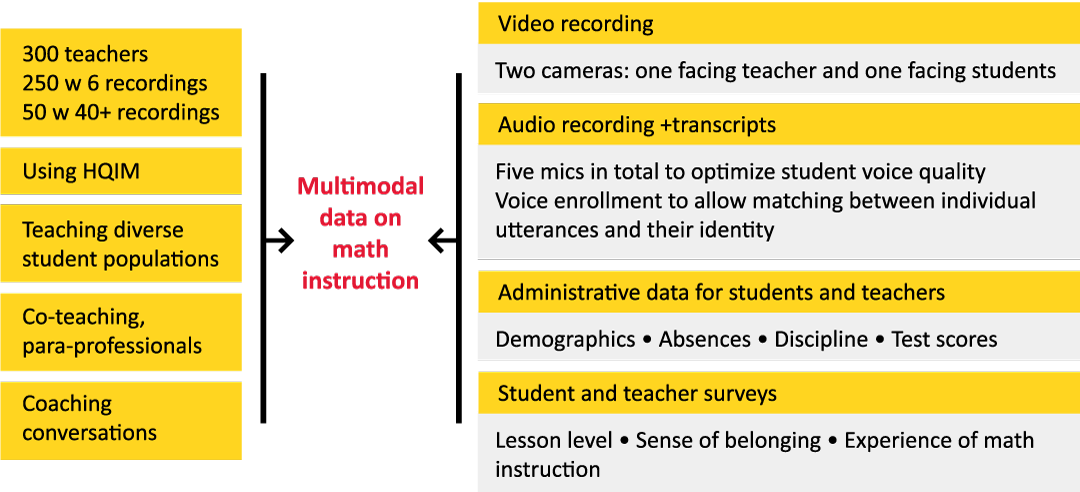
- High-quality multimodal (i.e., from many modalities) data sources: anonymized transcripts, audio, and video data, all linked to student demographics, classroom artifacts, student achievement, and student/teacher surveys.
- Detailed human annotations of key teaching moves and student mathematical practices that facilitate AI model development and tool building. Examples of excellent mathematics teaching align with standards and implement high-quality instruction materials (HQIM). Measures include high-leverage, equity-focused teaching moves such as acknowledging student competence and mathematical language routines, as well as examples of student-to-student talk about mathematics.
- User-friendly and accessible features: users can conveniently access de-identified data through a variety of open-source channels, with access to PII data through a dedicated data-sharing platform that supports AI model development.
How will we build this multimodal dataset?
Why does the field need a multimodal dataset like this?
A fast-growing literature has shown that natural language processing (NLP) techniques provide a potentially transformative approach for instructional measurement and feedback.Unlike conventional human-based classroom observations, NLP analysis of classroom transcripts can be done in scalable and adaptable ways. Scholars have primarily used the resulting transcript measures to provide private, on-demand feedback to teachers, which in some cases leads to positive impacts on educators’ instruction quality and selected student outcomes across different teaching contexts.
A parallel line of research has emerged to complement NLP transcript analysis by focusing on classroom videos. For instance, researchers have developed models to automatically recognize students' behaviors such as taking notes, using computers, or raising hands, as well as teacher nonverbal behaviors. These visual analyses provide insights into the physical and nonverbal aspects of classroom dynamics that complement the verbal information captured in transcripts.
However, relying solely on either transcripts or videos provides an incomplete picture of the rich, multimodal nature of classroom interactions. The future of AI in education lies in leveraging data that combines audio, visual, and potentially other forms of classroom information to provide a more comprehensive understanding of classroom dynamics for AI model development. Recent advancements in AI have shown that models trained on diverse data types can capture more nuanced information, which can support more accurate and more effective feedback for teachers, among a range of potential uses. The field desperately needs a high-quality, multimodal dataset to support the development of these more advanced applications of AI in education.